Since MacPorts’ move off Apple’s MacOSForge in October, we have been running MacPorts’ Trac installation on our own infrastructure. We used to rely on server and admin time generously donated by Apple. Now that we no longer enjoy this luxury, we are on our own when it comes to keeping our infrastructure running.
For a few months, we were bedeviled by high server load apparently caused by our Trac installation and had a hard time figuring out the cause. Our monitoring showed a large number of HTTP requests and Trac’s response time would regularly take a nose-dive as soon as the backup started.
After a few attempts of tuning various knobs without too much success, I finally decided to grab the Apache access logs and run awstats on them. Since we rotate our access logs biweekly1 I only had 10 days of February for analysis, but even those 10 days revealed some pretty interesting data.
Between February 1st and February 10th, we had 648,004 hits classified as “viewed traffic” by awstats, as opposed to 7,788,704 hits of “not viewed traffic”. Viewers transferred 3.31 GB of data, while an astonishing 351.92 GB of bandwidth were used by bots.
Awstats’ “Robots/Spiders visitors” analysis also told us that our top three spider visitors were
- Baiduspider with 3,206,576 hits (+37 for
robots.txt) using 288.44 GB of bandwidth - YandexBot with 375,010 hits (+60), with 1.75 GB of bandwidth
- AhrefsBot with 219,847 hits (+17), which used 2.83 GB
For comparison, in the same time frame, Googlebot visited our Trac installation 40,777 (+21) times, causing 512 MB of traffic.
As these statistics show, Baidu did not only cause 81 % of our traffic, they also sent us about 3.7 requests per second on average. Using Apache mod_status spot checks I saw that requests coming from Baidu’s IP ranges would often crawl URLs in Trac’s repository browser (/browser) and history (/log). Since our move to GitHub, we only maintain these Trac modules to avoid breaking old links, but do not actively advertise them any longer. It seemed like a bad idea to spend that amount of traffic for a subsection of our ticket system that we only kept for compatibility.
As a consequence, we added an exclusion to our robots.txt2 for Baidu and continued watching our statistics. As an image is worth a thousand words, here are some excerpts from our monitoring that visualize the effect. I added the block around midnight on February 11th.
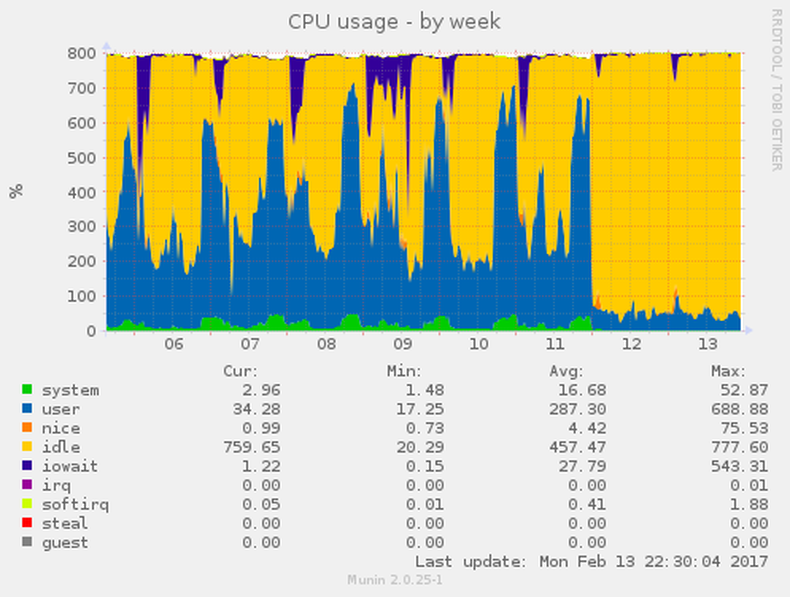
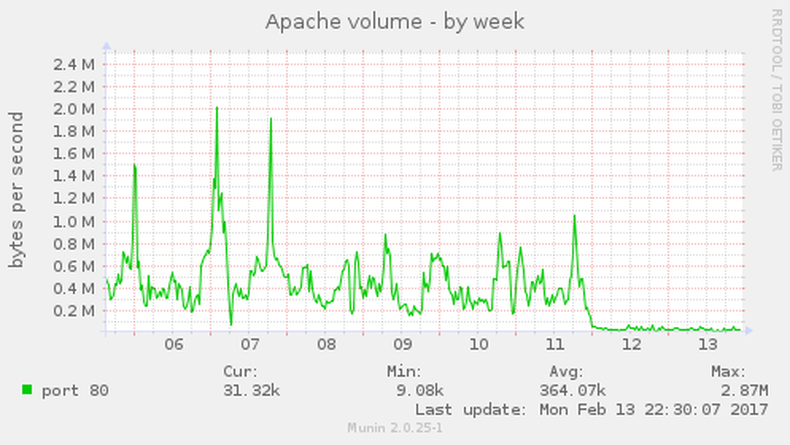
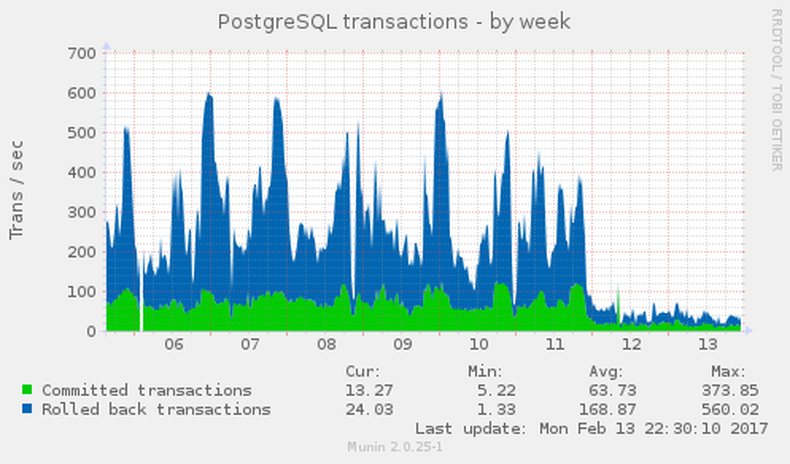
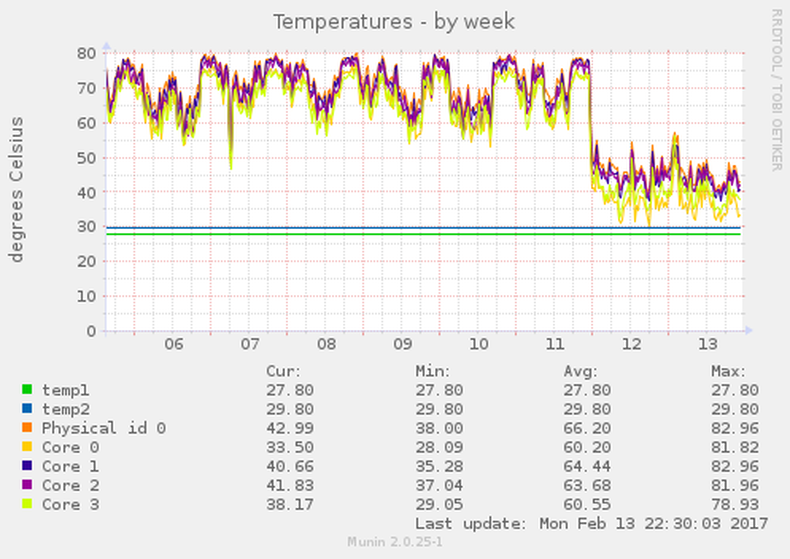
This leaves me wondering: How is that kind of crawling behavior acceptable and why has Baidu not improved their detection of similar content under dynamic URLs?
This is a conscious decision; we neither need, nor want more data. 2: There is some doubt online on whether Baidu respects robots.txt and I wanted to see quick results, so I also reconfigured our webserver to deny access to the /browser and /log URLs for Baidu’s IP ranges. Spot checks in mod_status seem to indicate that Baidu in fact respects the blocks in robots.txt after a few days, just as their documentation states.